Let’s do some language lawyer questions. I came across this on Reddit a while ago. The author gave it a very chuunibyou (edgy) name (, I went through them in my free time and ported them over here.
Original repository: https://github.com/0xd34df00d/you-dont-know-cpp
Assigning to references
Does this work? If it doesn’t, why and what’s the easiest fix?
|
|
What about this one? If this one doesn’t, why and what’s the easiest fix?
|
|
The first one is correct, and the second one is wrong. Why?
According to the decltype rules
, we can deduce the following:
| Syntax | decltype Deduction Result |
Value Category | Deduced Return Type | Result |
|---|---|---|---|---|
return fields...[Idx]; |
Rule 1: decltype(entity) |
id-expression | int (by value) |
Yields a prvalue, error |
return (fields...[Idx]); |
Rule 2: decltype(expression) |
lvalue | int& (by reference) |
Yields an lvalue, valid |
Without parentheses, fields...[Idx] is an id-expression. It triggers the decltype(entity) rule. For structured bindings, the compiler directly extracts the underlying type of the variable it binds to. Here, the underlying type is int. Therefore, decltype(auto) deduces the function’s return type as int. The function returns a prvalue, and you cannot assign a value to a prvalue.
When we add parentheses, the parentheses forcefully change its grammatical property, making it an lvalue expression. At this point, the compiler triggers the decltype(expression) rule. Because the expression is an lvalue, the standard dictates that decltype must deduce it as a reference type, int&. Therefore, the function returns a reference to the original data, making the assignment operation completely valid.
I found a very detailed blog post demystifying this: C++ value categories and
decltypedemystified: https://www.scs.stanford.edu/ ~dm/blog/decltype.html
Defaulted equality
Does this work?
|
|
Does this work?
|
|
<=> is a new feature
introduced in C++20. Its core idea is that instead of returning a bool upon comparison, it returns an ordering relationship. This is a very convenient feature that makes overloading operators a lot easier. It is an abstraction that I really like.
Here is an example: https://godbolt.org/z/34EjovMca
In section 3.2 of this clause , it states:
If the member-specification does not explicitly declare any member or friend named operator==, an == operator function is declared implicitly for each three-way comparison operator function defined as defaulted in the member-specification , with the same access and function-definition and in the same class scope as the respective three-way comparison operator function, except that the return type is replaced with bool and the declarator-id is replaced with operator==
In the first example, <=> is declared as default, so == is simultaneously declared. However, in the second example, since we didn’t provide a default implementation for <=> inside the member specification, the compiler won’t declare the == function for us. Even if we supplement the implementation of <=> later on, == still relies on us implementing it manually.
Specialization fun
You have this in your header:
|
|
How can this bite you?
It’s alright if only one TU includes this header.
But if more than one does, the linker might complain
on a CWG 2387-conforming implementation:
a fully specialized variable template (the one for std::vector<bool>)
is a variable definition, so all the usual variable linkage rules apply.
The fix is to add inline to that line only:
|
|
Also, constexpr doesn’t help: unlike constexpr functions,
constexpr variables are not implicitly inline.
Bonus points for …
… immediately thinking “unless they are static class data members, of course!” when reading the previous sentence.
requires-constrained return types
|
|
Dummy<> does not typecheck. Do you expect it to not typecheck? Why it does not typecheck and how to fix it?
Solution constraint
No, you are not allowed to hide it under auto + deduced type. For the actual type in the actual use case that prompted writing this, the return type then needs to be written in every branch, and it’s annoying, and also reduces discoverability of the API.
It seems like this would perfectly trigger SFINAE, but note that in std::optional<Args...> foo, if Args... is empty, this becomes a hard error, exactly as the compiler outputs: Too few template arguments for class template 'optional'.
How do we fix it?
We can use a base class DummyBase to wrap it, and then specialize Dummy based on the pack size, like this: https://godbolt.org/z/vdPsojqv3
We can also use a helper type to wrap it, ensuring that the type inside optional is never empty, like this:
|
|
Bonus question
Some usual approaches don’t work:
- Making
fooitself a template with a default template parameter, likeis not well-formed since packs can’t have default values.1 2 3template<typename... MyArgs = Args...> requires(sizeof...(MyArgs) == 1) std::optional<MyArgs...> foo() - Using something like
template<typename T = std::tuple_element_t<0, std::tuple<Args...>>and then havingstd::optional<T>in the “unary”foo()case:std::tuple_element_thard-errors on out-of-bounds index instead of merely being SFINAEd away. - A C++26 variation of that with pack indexing with
template<typename T = Args...[0]>: out-of-bounds in pack indexing is also somehow a hard error instead of being SFINAEd away.
Given this, what can you say about orthogonality and well-thought-ness of C++?
hhh, hard to say.
Is this valid?
|
|
Answer: see this bugzilla entry .
To allow us to use variables defined later in class member functions, the compiler won’t process two things immediately until the entire class definition is finished. First is the initial values of class member variables, and second is the default arguments of functions (requiring constructors).
In this code, since doSmth is still inside the class and our Nested doesn’t have a constructor yet, once we write const Nested& = Nested{}, it means we require Nested to have a constructor. What is this? A circular dependency. All options exhausted, sad.
Understanding the principle, it seems easy to fix: we just need to manually add a constructor to Nested. However, the following code will still have errors:
|
|
Because declaring a constructor as default is not the same as explicitly stating that our Nested class has a constructor like Nested() {};. default does not mean the Nested class will definitely have a constructor; it depends on the class’s implementation.
It is worth mentioning that MSVC will compile this successfully, hahahaha.
Some covariance
Is this valid?
|
|
Sure: this is covariance in action.
What about this?
|
|
Yep, also good: in some sense, Base* is a subtype of const Base*.
And, of course, Derived* would’ve worked too.
Now, this is surely valid too, right?
|
|
Nope: non-class types play by different rules, because otherwise the language would’ve been too consistent (see https://eel.is/c++draft/class.virtual #8).
So the question is, how do we implement this correctly?
An obvious idea is to wrap our int, but this isn’t generic enough and is too cumbersome.
Uh, if we ignore the runtime environment, we can solve this problem very well using CRTP:
|
|
Are there other methods? We can also handle it like this:
|
|
Writing it this way is obviously very ugly…
constexpr string literals
Does this compile?
|
|
Here the answer is easy: it’s an open question, discussed in CWG #2765 .
You might get Static assertion expression is not an integral constant expression because it is comparing string addresses.
If you want to compare them, please do not use auto.
When is this function safe or unsafe to use?
|
|
To be honest, I’m hallucinating a bit seeing this:
|
|
It’s safe for class types and unsafe for, say, ints.
For some reason the standard threats them differently, so
|
|
Finding the corresponding clauses in the standard is left as an exercise for the reader.
Maps of non-copyable, non-movable types
Suppose you have a type that’s not copyable nor movable, like
|
|
Suppose you need a hashmap mapping from int to ThreadedResource. One approach is to wrap ThreadedResource with shared_ptr, like std::unordered_map<int, std::shared_ptr<ThreadedResource>>. A null pointer indicates no mapping here.
This is annoying (?) because it incurs additional memory overhead and indirection, leading to a performance drop.
Can you do better?
One possible answer is to use std::optional, which can express “no value” more clearly.
Because the object cannot be moved, we have to use piecewise construction (piecewise_construct):
|
|
Please note that the order of the fields in ThreadedResource is mutex after handle.
Therefore, there is no need to pass an initializer to mutex, and everything will work fine.
Incrementing enums
Is this valid?
|
|
Although we cannot increment an enum directly, we can overload the ++ operator for the enum.
For example:
|
|
operator new
Is this valid?
|
|
How about this?
|
|
Obviously incorrect. The new operator is implicitly static, and at this point, n has not been fully created yet. Since the object doesn’t exist, where does the memory allocation come from? For virtual functions, similarly, there is no vtbl at this point.
How are these two functions different?
|
|
mkT1 is copy-list-initialization
, and mkT2 is direct-list-initialization.
The direct difference between them lies in the handling of explicit constructors. The mkT1 function does not allow calling constructors marked as explicit.
Moreover, before C++17, T{} would create a temporary object, which caused things like std::mutex to be unusable here.
Is this code valid?
|
|
This also involves C++ initialization. Before C++20, a class was considered an aggregate if:
- It has no user-provided constructors
- It has no private or protected non-static data members
- It has no base classes and no virtual functions
Here, Foo() = delete is user-declared, but not user-provided. So it is treated as an aggregate. In aggregate initialization, the compiler bypasses the constructor and directly assigns values to members without needing a constructor.
This leads to the above seemingly unreasonable code being able to compile under the C++17 standard.
Btw, C++20 modified the definition of aggregates, and the above code cannot compile in C++20 and above.
(^=…=^)
What does this code do, and on what features of C++17 does it rely?
|
|
This title makes me hallucinate our reflection [:O_o:]
This code is very hard to read. Actually, there’s a lot of such unreadable code in C++ templates…
It relies on variadic templates, fold expressions, and the evaluation order of the assignment operator. Simply put, if we call foo(func, 1, 2, 3), it will sequentially call func(3), func(2), func(1).
Let’s explain it in detail.
Suppose we call foo(f, t1, t2). (_ = ... = (f(ts), 0)) is a binary left fold. Its structure is (Init op ... op Pack).
After expansion, it looks like this: ((_ = (f(t1), 0)) = (f(t2), 0)). According to the C++17 standard, in the expression A = B, B is evaluated before A. So it executes t2 first and then t1.
What’s wrong with this code? When we secretly overload operator, or operator=, there might be problems.
Of course, there is one biggest problem: the readability is just too, too poor…
Conceptual concepts
Assume the following declarations:
|
|
-
Is
f(1, 2)valid? If yes, what would it print? -
What if
Trivial<T> && Trivial<U>is replaced byTrivial<T> && Trivial<T>in the second definition? -
What about
Trivial<T> || Trivial<U>? -
What if the definition of
Trivialgets “inlined”, replacing allTrivial<T>s withsd::is_trivial_v<T>?
The answer is 2,
|
|
For 1, it’s ambiguous.
Fun with fun templates
What does bar1 print?
|
|
What if we reorder the definitions, as in bar2?
|
|
Can we still specialize the first template after we’ve introduced the second one?
Yep:
|
|
Let’s talk about this together with the one above. These are notes I took back when I learned template metaprogramming:
During the specialization of class templates, the compiler will first convert the template into a function template and use function template overloading to determine priority.
Function template partial ordering rules:
If template B can handle all situations that template A can handle, but template A may not be able to handle situations that template B can handle, then template A is more specialized than B.
The article roughly means: the compiler fabricates a type U, substitutes type U into template A to generate a concrete function signature. Then it uses this function signature to try and match template B. If it matches, it means A is more specialized than B. Doing this in reverse allows comparing the specialization degree of A and B.
|
|
If we want to compare the specialization degree of #1 and #2, first, try substituting #2 into #1. We use a template argument U (e.g., int) to substitute into #2. That is, template <typename T = U> void foo(U *); (foo(int *)). Then try to substitute U* into #1, which is template <typename T> void foo(U *) (you can imagine foo(int *) trying to match #1). At this time, T in #1 can be deduced as U*.
Then, we try substituting #1 into #2. Similarly, substitute a template argument U into #1: template <typename T = U> void foo(U); and try to match it with #2, resulting in T* = U -> Failed.
In conclusion: the specialization degree of #2 is higher than #1.
Function templates can be both overloaded and fully specialized. Every overload of a function template is a primary template. During instantiation, overload resolution is performed first, followed by specialization matching. This means that during the overload resolution phase, only primary templates are considered, not their full specializations. After a primary template is selected, specialization matching occurs. Such rules lead to this: if the position of the template specialization is different, the ultimately matched template might also be different. Therefore, we shouldn’t use full specialization of function templates, but rather function overloading.
Applying it here:
The analysis below is by AIGC.
|
|
foo(&test):- Primary templates
#1(T=int*) and#2(T=int) are both in the candidate list. - According to the partial ordering rules,
#2is more specialized than#1($T*$ is better than $T$). - Select
#2. Since#2has no specialized version here, it returns 3.
- Primary templates
foo<int>(&test):- Explicitly specify
T=int. Only#2matches (foo(int*)). Returns 3.
- Explicitly specify
foo<int*>(&test):- Explicitly specify
T=int*. #1becomesfoo(int*), which matches.#2becomesfoo(int**), which doesn’t match.- Select
#1. Check#1’s specializations, findfoo(int*), and return 2.
- Explicitly specify
Result: 332
|
|
Note: Here, the full specialization template<> int foo(int*) will associate with the currently best-matching primary template, which is #2.
foo(&test):- Select primary template
#2. Check its specializations, findfoo(int*). Returns 2.
- Select primary template
foo<int>(&test):- Select primary template
#2. Check its specializations, findfoo(int*). Returns 2.
- Select primary template
foo<int*>(&test):#1matches,#2doesn’t match.- Select
#1.#1has no specialization here. Returns 1.
Result: 221
I C memset
Assume an instance of a struct is memseted to zeroes. What would be the value of the padding?
Further assume a field of that structure is updated. What would be the value of the padding after that field? After other fields?
They are all unspecified.
To understand this more intuitively, let’s look at its memory model.
Suppose we have such a struct:
|
|
After we finish memset:
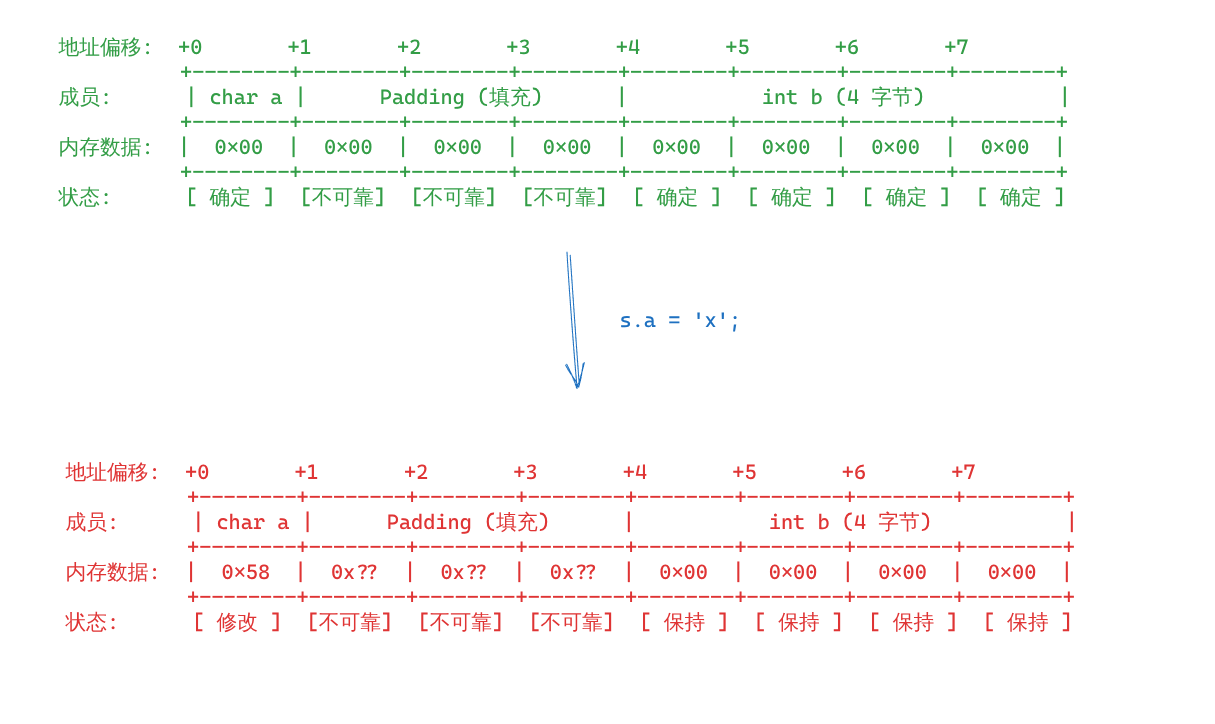
As shown in the figure, whether before or after executing s.a = 'x';, the value of the padding bits is unreliable. Why? Shiranai (I have no idea). But since the standard dictates it this way, don’t rely on this behavior (would people really not rely on it?).
Anyway, on my computer:
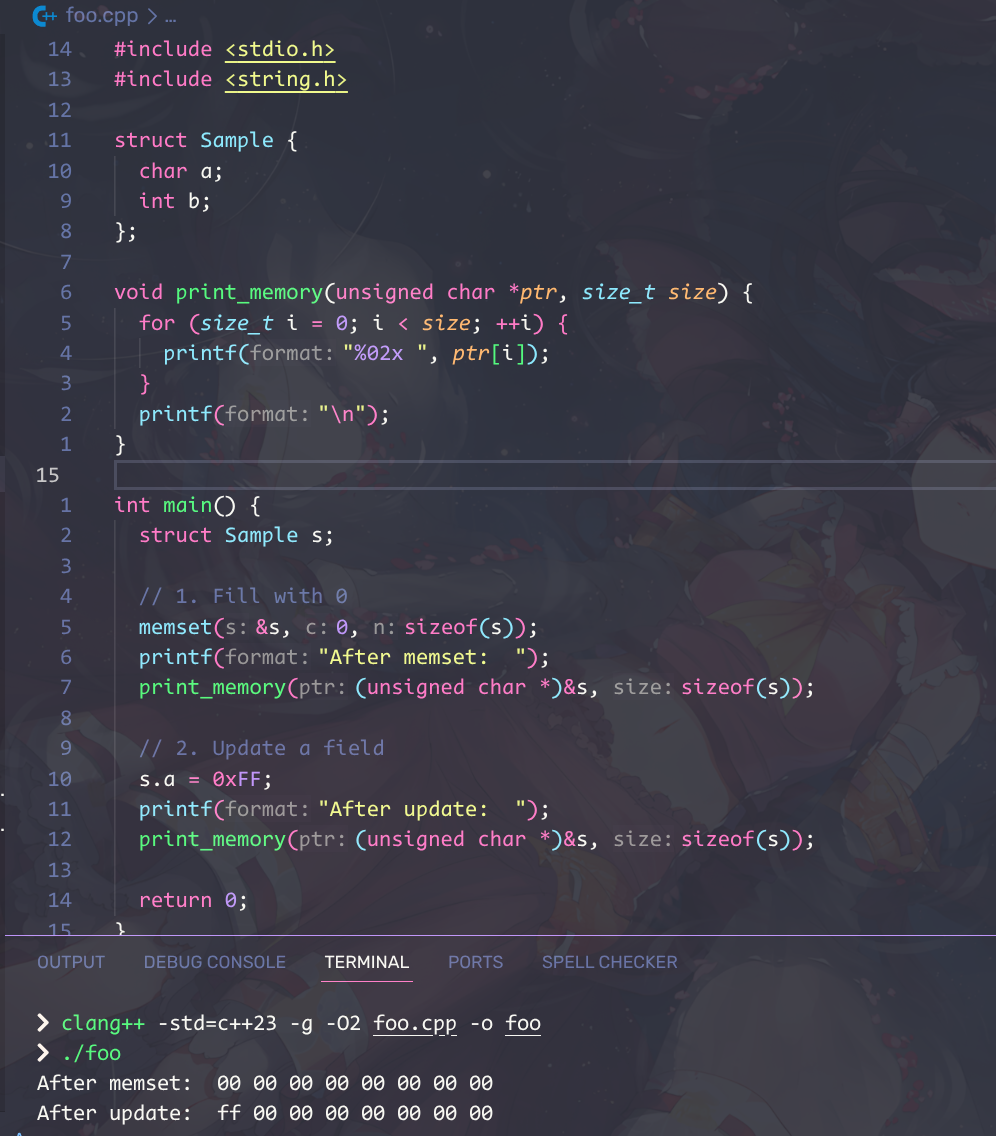
Is this code valid?
|
|
What about this one?
|
|
The first one is invalid, the second one is valid. But be careful not to do this:
|
|
Which lines are UB, if any?
|
|
I found a slightly older GCC version https://godbolt.org/z/bTE77GEs3
You can observe that 11, 21, 31, 32 are all UB.
11, 12, 13 are UB, which is obvious. But why is 32? (Note: referring to foo32)
It involves user-provided constructors https://eel.is/c++draft/dcl.fct.def.default .
According to the C++ standard, providing a constructor outside the class is considered a user-provided constructor. For user-provided constructors, the compiler calls that constructor directly and no longer performs additional zero-initialization.
Therefore, if you implement a constructor outside the class, it’s best to manually initialize all members.
Is this code valid?
|
|
Depends on the C++ version, and whether it is C++ to begin with.
Up until C++17, neither an x object nor an int subobjects are created, and this code is UB.
Starting with C++20, an x object and its int subobjects are implicitly created, and this code is valid.
It always has been valid C code, though.
I thought this was correct (after all, I’ve only written code like this in C).
Before C++20, malloc did not create objects. When accessing p->a, a real X object does not exist at that memory address. Objects must be explicitly created using new.
If we want to write it correctly:
|
|
Is using this function dangerous?
|
|
What about this one?
|
|
This one?
|
|
Nope, nope, yep.
Why? What’s the crucial difference between these functions? Is there any difference in their types?
Accessing any element of the “array” returned by foo1 and foo2 is fine.
Try doing that to foo3 and you’ll get an UB, since you’ll be using an object whose lifetime has ended!
foo1 and foo2 return a pointer to a string that is, roughly speaking, allocated and stored somewhere in the executable at compile time.
The pointer returned by foo3 references the local array str which is initialized by copying that same string.
This array is local to foo3 and its lifetime ends once the function has returned, hence the UB.
While modern compilers output a warning, what’s a reliable and somewhat general way to check functions like this?
Mark all these functions constexpr and try using them in a constant evaluated context, like static_assert:
|
|
Say, clang outputs:
|
|
What does this print?
|
|
borrowed from Arthur O’Dwyer’s blog, where he also considers this in more detail
The output is CoreLibrary.
This is probably a very cliché topic, but it is demonstrated rather subtly here. Usually, std::swap is used to explain ADL and CPO.
CPO and tag invoke are relatively important features in modern C++, and ranges heavily uses CPOs in its implementation.
Are these functions different?
|
|
Would f() be a good function? (
In fact, f is UB, while g is fine.
borrowed from Daniil Zhuravlev’s blog, where
he explains what language in the C++ Standard makes it UB and shows a proof that function f is fishy
Conclusion
I must be crazy to have actually finished writing this. If you ask me: “If I learn all of this, can I become a C++ guru?”, I think not. After all, obsessing over obscure language features will most likely just make you an obsessive fanatic.
I’m tired :) Take a break.

P.S. The English text above was translated by a Large Language Model without manual proofreading. Please excuse any unnatural phrasing or slight losses in the original emotional nuance.